Look ma, no CUDA! Programming GPUs with modern C++ and SYCL
July 21, 2019Back in 2009 when I began doing real work with GPGPUs and CUDA in the context of large scale HPC simulations, the developer experience was dreadful. Sure, for the right algorithm and after lots of blood and tears, performances usually turned out excellent. But before production, comes the poor developer.
Debugging CUDA kernels was a nightmare: whenever I had to track down a bug I had to fire up a dedicated gaming rig (bought just for that purpose) because debuggers needed two identical GPUs to work (when they actually worked, and that happened only if you spelled your prayers right the night before). Compilers segfaulted all the time. Generated PTX assembly was often incorrect (just imagine debugging correct C++ code that has been wrongly translated by your faulty compiler, on a weird hardware you can’t really observe, with poor tooling support).
On top of that depressing experience, one of the main CUDA goals was clearly to be an efficient vendor lock-in tool. Once you invested effort and money on CUDA, you’re stuck with NVIDIA hardware.
Luckily, during the last ten years the GPGPU tooling ecosystem improved a lot. Compilers
have become stable, debuggers are now usable, we even have
PTX backends
in toolchains other than nvcc, a plethora of alternative approaches emerged and keep
pushing to gain market (I would say that OpenCL is
the most notable one, among others).
In late 2018, almost ten years after my first encounter with GPGPUs, I came across this new (to me) thing called SYCL. The official description says:
SYCL (pronounced sickle) is a royalty-free, cross-platform abstraction layer that builds on the underlying concepts, portability and efficiency of OpenCL that enables code for heterogeneous processors to be written in a single-source style using completely standard C++. SYCL single-source programming enables the host and kernel code for an application to be contained in the same source file, in a type-safe way and with the simplicity of a cross-platform asynchronous task graph.
Sounds interesting, isn’t it?
At that time I couldn’t exactly figure out its actual adoption in the wild, was it widespread in other markets or simply a niche thing? It was maybe the next big thing that no one wanted to actually use in the real world?
And then this happened:
Intel’s ‘One API’ Project seeks to deliver a unified programming model to simplify application development across diverse computing architectures and incorporates #SYCL https://t.co/hJegAZ7u4E pic.twitter.com/544wKoJj0k
— Khronos Group (@thekhronosgroup) June 20, 2019
Intel announced to the world that their common programming model intended to target the whole heterogeneous system, from GPUs to FPGAs to regular x86 CPUs, is going to be based on SYCL. It looks like they are actively investing an interesting amount of effort on it and they’re doing a lot of work to integrate into upstream LLVM their own SYCL implementation.
At this point, all the experiments and prototypes I was doing during my daily job assumed a totally different perspective.
What does SYCL look like?
For those familiar with OpenCL (and CUDA to some extent), SYCL is built on the same concepts: it borrows the same device and execution models straight from OpenCL, which in turn is extremely similar to CUDA. Let’s just have a look at a simple kernel that performs an element wise sum between containers:
// Kernel type tag
// Be sure to define it in an externally accessible
// namespace (e.g.: no anonymous)
template <typename>
struct AddKernel {};
template<typename ContiguousContainer>
void add(const ContiguousContainer& a, const ContiguousContainer& b,
ContiguousContainer& result) {
using std::data,
std::size;
using value_type = std::remove_cv_t<std::remove_reference_t<decltype(*data(c))>>;
using kernel_tag = AddKernel<value_type>;
// Queue's destructor will wait for all pending operations to complete
cl::sycl::queue queue;
// Create buffers (views on a, b and result contiguous storage)
cl::sycl::buffer<value_type> A{data(a), size(result)};
cl::sycl::buffer<value_type> B{data(b), size(result)};
cl::sycl::buffer<value_type> R{data(result), size(result)};
// The command group describes all setup operations needed
// to execute the kernel on the selected device
queue.submit([&](cl::sycl::handler& cgh) {
// Get proper accessors to existing buffers by specifying
// read/write intents
// (note that A, B and R are captured by reference)
auto ka = A.get_access<cl::sycl::access::mode::read>(cgh);
auto kb = B.get_access<cl::sycl::access::mode::read>(cgh);
auto kr = R.get_access<cl::sycl::access::mode::write>(cgh);
// Enqueue parallel kernel
cgh.parallel_for<kernel_tag>(
cl::sycl::range<1>{size(result)}, // 1st parameter: the kernel grid
[=](cl::sycl::id<1> idx) { // 2nd parameter: the actual kernel
// We are in the kernel body:
// this is the only code that gets compiled for device(s).
kr[idx] = ka[idx] + kb[idx];
}
);
});
// At this point our kernel has been asynchronously submitted
// for execution
// End of current scope: before actually returning, the queue destructor
// will block until all operations (copies and kernel executions)
// are completed. We are sure that when the function returns all the
// computed values have been transferred into 'result' and are available
// host-side.
}
Let’s quickly see at a very high level the essential building blocks needed by a SYCL program:
- tell SYCL where the host-side input and output memory your kernels are going to use is located by constructing buffers;
- construct a command queue, an object of type
cl::sycl::queuethat is going to be your steering wheel for all the execution devices that support kernel execution; - submit a unit of work in the form of a callable object (generated by
a lambda expression in this case, but everything that satisfies the
Callableconcept will do the job1) viacl::sycl::queue::submit().
At this point, we’re done: the callable object you just submitted is going to be executed on a device (more on this later). Well, we still need to see what is needed to define the proper unit of work we just submitted to the command queue:
- define our data dependencies: this is achieved by declaring
accessors, objects that tell SYCL about our intents on the
buffers we previously defined (
cl::sycl::access::mode::readfor read-only,cl::sycl::access::mode::writefor write-only); - invoke the actual kernel on the selected device via
cl::sycl::handler::parallel_for<>()template method. Just like we saw before for the submission to the command queue, the kernel is just an object ofCallabletype (more on the arguments later).
Now we are really done.
From this trivial example we can make some interesting observations about the SYCL programming model:
Modern APIs
Queues are drained, copies are finalized, destructors do their job: all SYCL objects are of RAII types, so we can call it modern (I would call it sane) with respect to types design.
Just standard C++11
Luckily enough, no weird keyword or syntax is involved, just standard C++11 code 2. Note that in the previous example all invocable objects are passed as regular lambdas.
Single source
Host and device code live in the same source file. It is a SYCL implementation’s
responsibility to split the C++ source file and forward each chunk of parsed code to the
right compilation backend (similarly to what nvcc does and as opposed to what OpenCL
APIs require) 3.
Data transfers are implicit
Unlike CUDA and OpenCL where explicit copies are required by the model, here we just
declare our read/write intent over cl::sycl::buffer and the SYCL runtime
deduces4 which buffers have to be transferred to and from host
containers 5.
This design principle affects also the execution order of kernels: SYCL command queues are required to be asynchronous and, while the actual execution order is unspecified, data dependencies across kernels are guaranteed to be satisfied by the runtime.
using cl::sycl::access::mode::read,
cl::sycl::access::mode::write,
cl::sycl::access::mode::read_write;
cl::sycl::buffer<T> A{/*...*/};
cl::sycl::buffer<T> B{/*...*/};
cl::sycl::buffer<T> C{/*...*/};
cl::sycl::queue queue;
// Kernel 1
queue.submit([&](cl::sycl::handler& cgh) {
auto in = A.get_access<read>(cgh);
auto out = B.get_access<write>(cgh);
//...
}
// Kernel 2
queue.submit([&](cl::sycl::handler& cgh) {
auto in = A.get_access<read>(cgh);
auto out = C.get_access<write>(cgh);
//...
}
// Kernel 3
queue.submit([&](cl::sycl::handler& cgh) {
auto in = B.get_access<read>(cgh);
auto inout = C.get_access<read_write>(cgh);
//...
}
What the runtime does here is that it builds the dependency graph of our kernels based on the data dependencies we implicitly declared among them by retrieving accessors. In this case the runtime deduces the following dependency DAG (arrow is a depends on relationship):
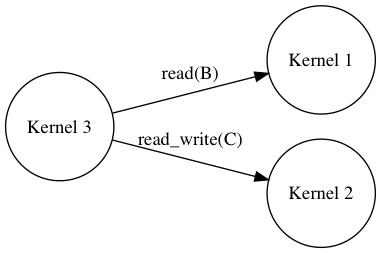
Given this situation, the runtime could execute Kernel 1 and Kernel 2 concurrently
while the data needed by Kernel 3 to carry out its work ensures that it is going to be
executed only after the completion of its dependencies.
Even in a trivial example like this where we submit a bunch of kernels, we can achieve maximum overlapping between non-dependent data flows on the DAG implicitly deduced from our buffer accessors. This looks extremely convenient compared to what happens in other paradigms where, in real world applications, a large amount of effort must be spent to achieve maximum overlapping between data transfers and kernel executions.
Kernels are launched over a grid
The implicit iteration space over which kernels are executed has shape and extent,
just like a CUDA kernel grid. Let’s have a look at the parallel_for call
(ignore kernel_tag6 for now):
// Enqueue parallel kernel
cgh.parallel_for<kernel_tag>(
cl::sycl::range<1>{size(result)}, // 1st parameter: the kernel grid
// ...
With the first parameter we are saying that the kernel grid will have
one dimension (the non-type template parameter) with extent
== size(result). In the same way as other paradigms work, with the
cl::sycl::range<1>{n} parameter we are launching a 1-dimensional vector
of execution units, one for each of the n output elements.
The SYCL standard brings so much at the stake, interesting bits like device selectors (customizable objects that decide on which actual device a kernel will be executed), error handling and reporting, n-dimensional kernel grids, device allocators, device atomics and a lot more, enough to write entire books on the subject. Just stop here for now, you get the general idea.
Challenges
As clearly pointed out by Justin Lebar (one of the authors
of the clang’s PTX backend): CUDA Is a Low Level Language. And that is perfectly
understandable: the accelerated portion of any application is going to be the hottest one,
that kind of hotspot that is usually carefully optimized, likely by hand, iteratively,
with the help of micro-benchmarks and packed with tricks and hacks that privilege
performance over clarity or maintenance and are obviously tightly related to the actual
hardware it targets. While SYCL claims to be portable and cross platform, just look at
the amount of extensions are being introduced to support FPGA targets
(cl::sycl::vendor::xilinx::dataflow for example,
here
in triSYCL): this is completely normal since FPGAs are weird beasts, radically different
from regular GPGPU architectures and so, in hot, accelerated code this profound difference
stands out clearly.
I think this is going to be a recurring pattern in real world, SYCL-accelerated code
bases: a bunch of different SYCL kernels, each one hand-optimized for a class of
architectures, a single architecture or even a specific product just like happens in CUDA
or OpenCL nowadays. In other words, I would say that SYCL has not performance
portability among its design goals.
Errata corige: thanks to Gordon Brown, who took part in the SYCL design process, I got some insights about this topic with respect to the original design goals that have been taken into account back in the early days.
Firstly, SYCL is built on top of other lower-level standards:
- OpenCL, from which SYCL inherits device and execution models;
- SPIR, the intermediate representation into which SYCL kernels are usually translated by the compiler. This sort of machine-independent assembly language, similar in scope to PTX and designed to efficiently represent massively parallel computations, is shared by other standards like Vulkan or OpenGL.
Contrary to what I was assuming, performance portability has been indeed considered as a very high priority design goal but, given that:
- the bulk of performance portability is delegated to lower level building blocks (OpenCL and SPIR) that have been designed from scratch for this purpose;
- when so diverse architectures must be taken into account, portability and performance are inherently antithetical and a trade off is needed;
SYCL designers acknowledged this unavoidable trade off and choose to fill this gap making sure that adapting a kernel to a new hardware platform would have been as straightforward, convenient and painless as possible.
Despite this inevitable shortcoming, SYCL still brings a lot of advantages, for example:
- convenience and developer sanity: it is just standard C++ code, no language extensions, no weird toolchains, tooling ecosystem readily available;
- host CPU backends are available from day one: they enable the applications to leverage both the host CPU and discrete accelerators and, maybe important alike, they provide easy debugging, observability and seamless deployment (e.g. you don’t have to buy some beefy gaming laptop just to be able to develop your stuff);
- a terse, modern and expressive API, miles ahead of the sheer verbosity of OpenCL;
- no vendor-lock in: your code can be run almost everywhere, from CPU-only and accelerated servers to Android phones. Even if NVIDIA could try to gatekeep SPIR-V support on their own platform, when in presence of CUDA hardware the compiler could just sidestep SPIR-V generation and go directly for the PTX backend to natively compile SYCL kernels for NVIDIA hardware 7.
Moreover, several open and closed source implementations are already available, each one with its goals and strengths:
- triSYCL, the reference implementation;
- hipSYCL, an alternative open source implementation originally targeted at AMD ROCm;
- ComputeCpp, a commercial (the community edition is available free of charge), closed source implementation by Codeplay;
- builtin clang support for SYCL, actively developed by Intel and aimed at being reintegrated in upstream LLVM.
To summarize the ecosystem, I will borrow this chart directly from the hipSYCL documentation:
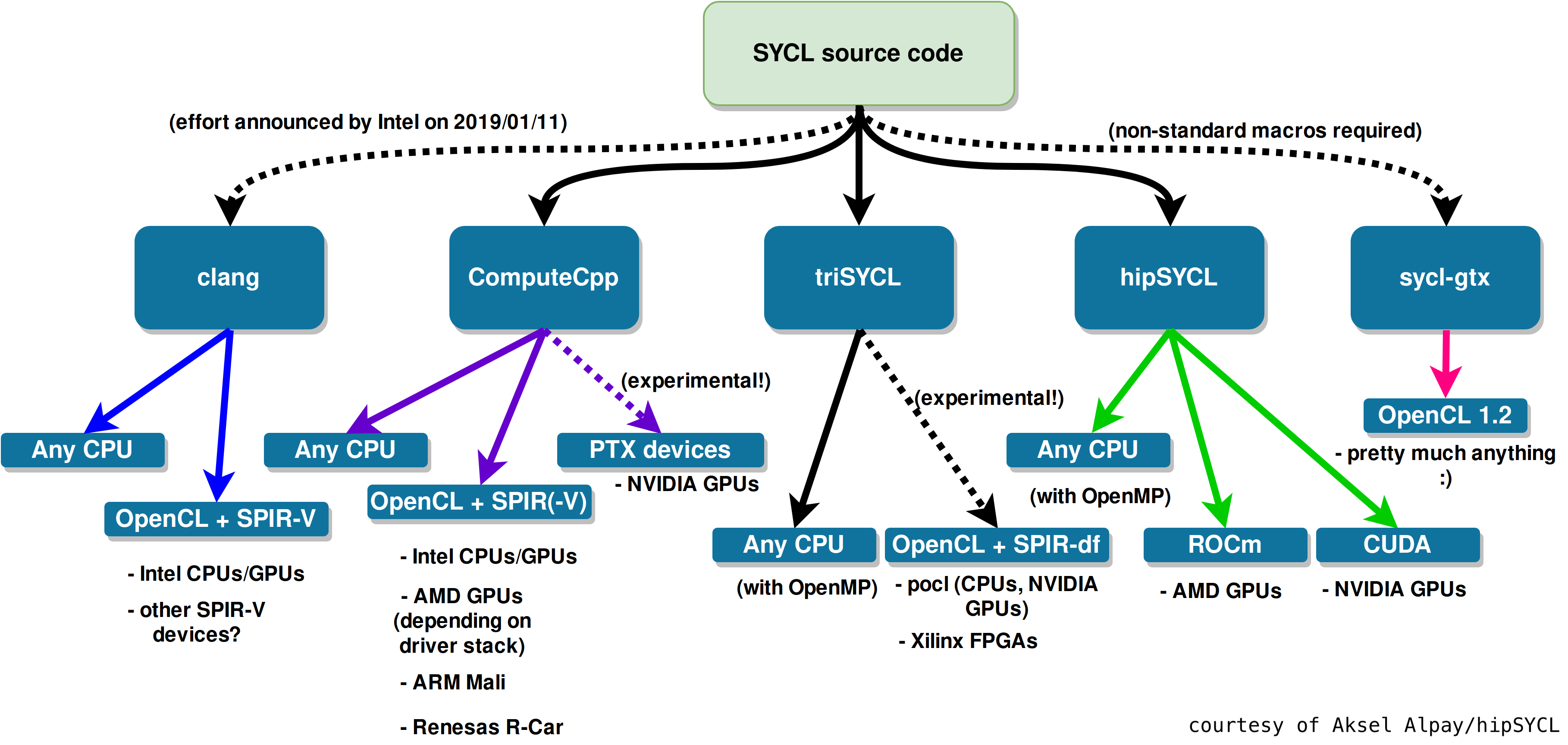
Wrapping up, I personally think that the first, realistic, valuable goal that SYCL can achieve is to establish both a standard platform and a common vocabulary for heterogeneous systems programming on which people coming from different industries and backgrounds can build communities, share code, tooling, build systems and, more importantly, break out from vendor lock-ins.
Of course, the most important question right now is:
Will it succeed?
Look ma, no CUDA! Programming GPUs with modern C++ @ Italian C++ Meetup
During the May 2019 meetup of the Italian C++ Community in Modena, I gave an introductory talk about the state of the art in GPGPU programming, the paradigms that emerged in the last ten years and what SYCL brings to the table and why we should care. You can find all the support material including examples, build scripts and the slide deck here, feel free to grab anything you happen to find useful. You can even see me prattle on (sorry, Italian only) here.
Credits
A lot of excellent charts, snippets and pitches have been taken directly from publicly available talks across the net, I’ve strove really hard to put proper credits but if you notice that something’s missing please drop a comment or open an issue on the repo.
I’m particularly grateful to (in order of appearance):
- Karl Rupp
- Michael Wong
- Gordon Brown
- Aksel Alpay
- Jeff Hammond
- All the C++ Meetup attendees and to Marco Arena for the chance to show some brand new cool stuff!
Thank you folks for your help in making slides and this post more clear and understandable.
Resources
sycl.tech: a comprehensive community platform that collects articles, blog posts, talks and everything related to SYCL that shows up on the web.- Accelerating your C++ on GPU with SYCL by Simon Brand - one of the nicest introductions around.
- Programming GPUs with SYCL by Gordon Brown - a great introduction to the whys and hows of SYCL.
- SYCL Developer Guide by Codeplay - the current lack of learning material about SYCL is disappointing but this terse developer guide makes the situation a little better (you can also download PDFs of it).
- CppCon 2018: Parallel Programming with Modern C++ by Gordon Brown - a great overview of parallel programming and modern C++.
- Modern C++ for accelerators: a SYCL deep dive by Andrew Richards - an excellent slide deck to be printed and studied.
- 2019 EuroLLVM Developers’ Meeting: A. Savonichev (Intel) “SYCL compiler: zero-cost abstraction and type safety for heterogeneous computing” - a nice insight on how Intel is working on his own SYCL implementation for LLVM; mandatory for compiler nerds.
- SYCL 1.2.1 API Reference Card - print and hang it on the wall next to the Picasso you just bought at Sotheby’s.
- SYCL Standard Specification - to be a proper standard, you need a proper spec. Not so standardese (a straightforward and educational read, actually) but definitely not a novel.
- GCC support for offloading to PTX via OpenACC
- Compiling CUDA with clang - LLVM 9 documentation
- CppCon 2016: CUDA is a low-level language by Justin Lebar
gpucc: An Open-Source GPGPU Compiler- John Lawson et al., Cross-Platform Performance Portability Using Highly Parametrized SYCL Kernels - a very nice article about parametrizing SYCL kernels to achieve good performance portability across architectures.
-
…everything that satisfies the
Callableconcept and accepts an argument of typecl::sycl::handler&. The handler is your source of information about the execution context you’re in (e.g.: on which device you’ve been actually scheduled). ↩︎ -
the SYCL specification is actually based on C++11 but this restriction applies only to the body of the kernel lambda, e.g. the only code that is going to be actually compiled by device backends. In the example I used some C++17 library stuff (
std::data()for instance), and it is ok as long as the host frontend supports it. ↩︎ -
while totally invisible to the user, the standard specification allows two different workflows for compilation:
- separate compilation: a frontend driver splits the C++ source and calls different device compilers under the hood before linking everything together in a fat binary;
- single source compilation: the actual compiler frontend parses the input translation unit just once (remember that we are dealing just with standard C++11 code) and then forwards the lowered representation to all the device backends involved. For example, hipSYCL used to rely on separate compilation using via a python script to carry out all the orchestration but they recently moved to the single source compilation technique leveraging the clang plugin interface.
-
Jeff Hammond pointed out that while asynchronous is the default, we can actually force explicit data transfers by calling the
cl::sycl::handler::copy()method like he did here. ↩︎ -
since we are constructing non-owning views (
cl::sycl::buffer<T>acts exactly like astd::span<T>in this regard) over contiguous chunks of memory that have to be transferred across different address spaces, make sure that theContiguousContainerconcept is satisfied: while we wait for C++20 to bring proper concepts in, we can reasonably ensure the contiguous sequence (e.g.: contiguous storage) property just likeGSLdoes forgsl::span<T>). ↩︎ -
the
parallel_fortemplate is instantiated on an (empty) type, in this case calledclass AddKernel. This tag is used only to give the anonymous callable object generated by the lambda expression a unique, user-defined name on which (possibly) different compilers can agree on. Look at it as workaround to de-anonymize compiler-generated callable objects (or a way to haveexternlambdas). Please note that the tag itself is templatized on thevalue_typeof containers: each kernel template instantiation must be different, in other words be aware that kernels are just regular functions and so they must abide by ODR! ↩︎ -
in the original
gpuccpaper, Google claims that their open source PTX backend (now merged in upstream LLVM) is either on par or outperformsnvccfor all the workloads they took into account. ↩︎